Introduction
When running Liquidsoap in production, it is common to deploy many instances of the same script on the same server — one per stream, one per radio station, and so on. In that context, a 1% improvement in CPU or memory usage per instance can translate into a ~20% improvement across 20 instances, which may be the difference between needing more hardware or not.
This post documents an experiment in tuning three interacting parameters — settings.frame.duration, runtime.gc minor_heap_size, and runtime.gc space_overhead — to reduce both CPU and memory usage for a typical streaming script. It is exactly that: an experiment, not a recipe. The numbers are specific to one script, one server, and one workload. In practice, getting meaningful results requires a mix of systematic exploration (which the tooling below can help with) and pragmatic manual tweaking based on your own setup. That said, the test harness and methodology are general enough to be useful to others, which is the main reason for publishing this.
The script under test
The script being tested is a fairly typical relay+restream script: it takes one input.http source (an HTTP/Icecast stream) and pushes it to one output.icecast. No mixing, no effects, no complex routing. The operator deploying this script runs roughly 20 simultaneous instances, one per radio station, on a shared server — so any per-process savings compound quickly.
The script accepts three tuning parameters via command-line flags:
frame_duration = getopt(default="0.10", "-D")
settings.frame.duration := float_of_string(frame_duration)
minor_heap_size = getopt(default="16384", "-H")
space_overhead = getopt(default="40", "-O")
runtime.gc.set(runtime.gc.get().{
minor_heap_size = int_of_string(minor_heap_size),
space_overhead = int_of_string(space_overhead)
})
What these parameters do
Frame duration
settings.frame.duration controls how many seconds of audio Liquidsoap processes per streaming cycle. A larger frame means fewer cycles per second, which reduces per-cycle overhead (function calls, scheduler bookkeeping, etc.) and therefore CPU usage. The trade-off is that each cycle allocates a larger audio buffer on the heap. At 44100 Hz stereo, a 0.10 s frame is a float array of about 8820 samples, occupying roughly 57 KB.
The OCaml GC and why it matters
Liquidsoap is written in OCaml, whose garbage collector uses a generational strategy with two heaps.
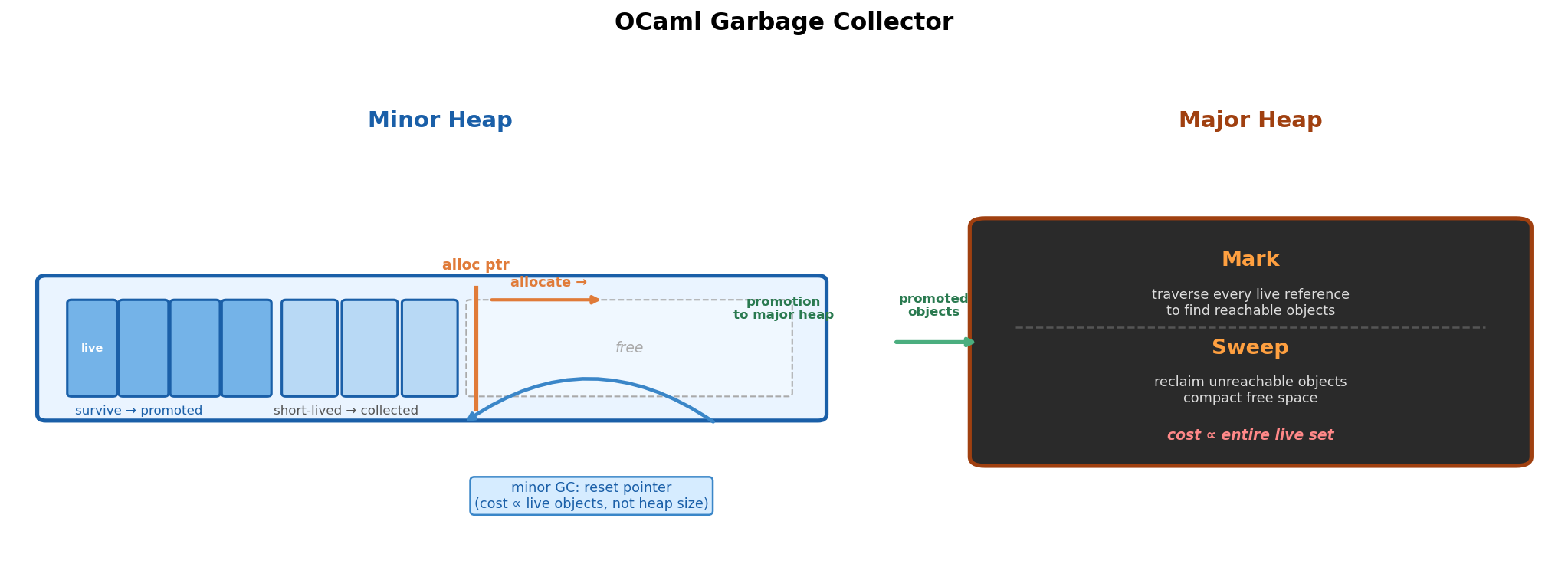
The minor heap is a small, fixed-size arena. Every new allocation simply moves an internal pointer forward — that is the entire cost of allocating. When the minor heap fills up, a minor collection runs: it scans the arena, moves any objects that are still reachable (live) to the major heap, and resets the pointer back to the start. The crucial point is that this reset is cheap because its cost is proportional to the number of surviving objects, not the total heap size. Short-lived objects — the vast majority — are simply discarded when the pointer resets, at essentially zero cost. Objects that survive this process are promoted to the major heap.
The major heap is a black box from the minor heap’s perspective: it holds promoted objects and grows dynamically. It is collected with a mark-and-sweep algorithm. Mark means traversing every live reference in the program to find all reachable objects — this requires visiting the entire live object graph. Sweep means walking the heap to reclaim the memory occupied by unreachable objects. Both phases scale with the size of the live set and the heap, making major collections significantly more expensive than minor ones.
The hypothesis behind the tuning in this post is: audio frame buffers are large OCaml float arrays, and they are the dominant allocation in a simple relay script. For a frame to be collected cheaply, two conditions must hold. First, it must fit in the minor heap so it is allocated there rather than directly in the major heap. Second, it must become unreferenced — i.e. the streaming cycle that produced it must have finished — before a minor GC runs. If both hold, the frame is simply discarded when the pointer resets: it never reaches the major heap and incurs no mark-and-sweep cost.
If the minor heap is too small, a minor GC may fire while the frame is still in active use. At that point the frame is live, so it gets promoted to the major heap — where it will eventually need to be traced and reclaimed by the more expensive mark-and-sweep collector. Sizing the minor heap generously enough to hold a full frame buffer, plus the other allocations happening during the same cycle, should keep frames in the cheap lane for their entire lifetime.
We have not directly validated this assumption — we did not instrument the GC to confirm that frames are staying in the minor heap. What we did instead is tune the GC parameters guided by this intuition and measure the end result: CPU and memory usage over time. The numbers came out in the direction the hypothesis predicts, which is encouraging, but the root cause could be analysed in more details.
minor_heap_size
This sets the size of the minor heap in words (1 word = 8 bytes on 64-bit). The default in OCaml is 256 KB (32768 words). The frame buffer must fit here for efficient collection. A 0.10 s stereo frame at 44.1 kHz is ~57 KB, so a 128 KB minor heap (16384 words) fits it with room to spare. Going smaller (32 KB) means the frame no longer fits and gets promoted immediately to the major heap. Going larger than necessary is also counterproductive: a bigger minor heap takes longer to fill, so minor GCs run less often, and more garbage accumulates before being collected — increasing the process’s memory footprint.
space_overhead
This controls how aggressively the major GC runs. It is roughly the ratio of wasted space (live objects + free fragments) to live objects, expressed as a percentage. A value of 40 means the collector runs more frequently, keeping the major heap compact — but more frequent major GC means more CPU spent on mark-and-sweep. A value of 120 means the major heap can grow larger before being collected, reducing GC frequency and CPU cost but increasing memory usage. For our use case, a lower value trades a measurable but modest increase in CPU for meaningfully reduced memory — and the measurements confirmed the trade-off is worth it.
The experiment
We ran a full 3-axis parameter sweep: 5 frame durations × 5 minor heap sizes × 5 space overhead values = 125 combinations, each running for 5 minutes (5 in parallel at a time). CPU and memory (RSS) were sampled every 5 seconds via ps.
The test harness is two self-contained bash scripts — they launch processes in batches, monitor them, hard-kill them at the end of each batch, compute per-combination averages and standard deviations, and generate heatmaps and a Pareto scatter plot. Both scripts were generated with the help of an AI assistant.
run_matrix.sh— full 3-axis matrix sweep (frame duration × minor heap size × space overhead)compare3.sh— three-way head-to-head comparison over a fixed duration
Results
Heatmaps across the full matrix
The heatmaps below show average CPU (%) and average memory (RSS in MB) for each combination of frame duration, minor heap size, and space overhead.
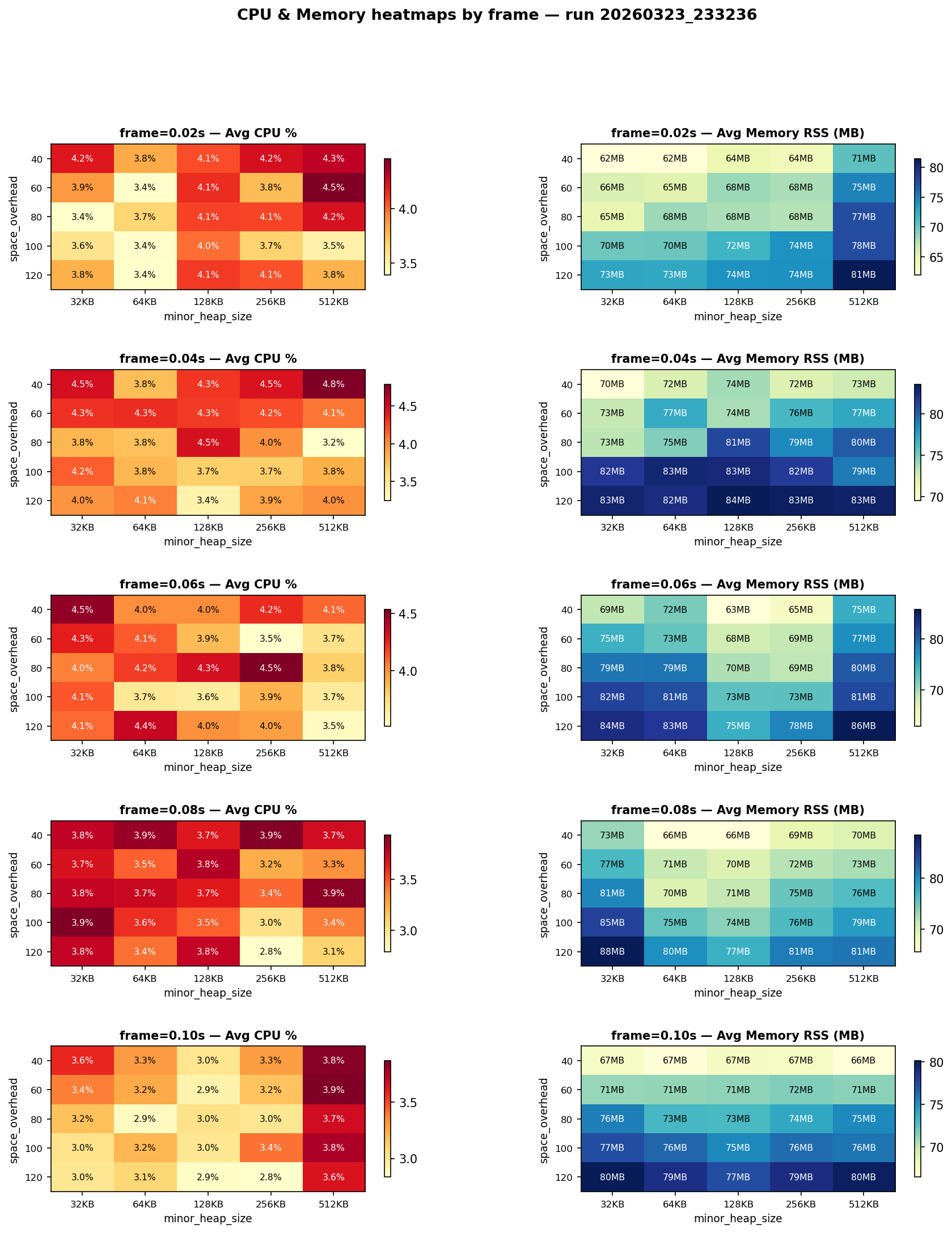
A few things stand out:
- Larger frame duration reduces CPU, as expected — fewer scheduling cycles per second.
- Memory is not simply determined by frame size: for frame=0.06 s, minor heap sizes of 128 KB and 256 KB (which comfortably hold the ~42 KB frame buffer) show noticeably lower memory than 512 KB or the too-small 32/64 KB heaps. This confirms the minor heap threshold effect.
- Higher space_overhead always increases memory — no surprise there — but the CPU savings from less frequent major GC are largely negligible at the scale of this script.
Pareto front
We computed the Pareto front across all 125 combinations, optimising for minimum average CPU and minimum average memory simultaneously.
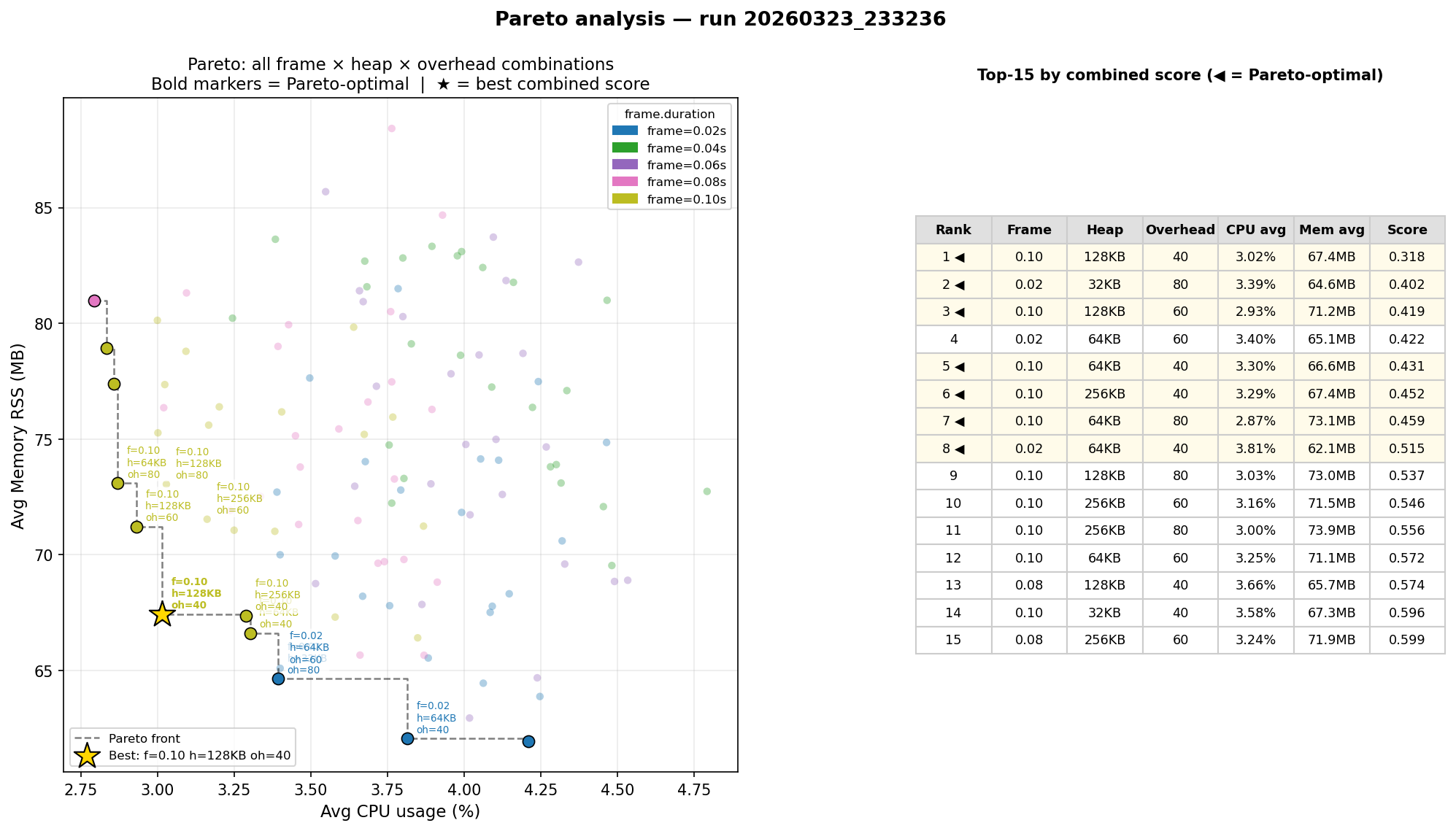
The full Pareto front has 10 points. Here are the top 4 by combined normalized score:
| Rank | Frame | Heap | Overhead | CPU avg | Mem avg | Score | |——|—––|––––|–––––|———|———|—––| | 1 | 0.10s | 128 KB | 40 | 3.04% | 68.2 MB | 0.354 | | 2 | 0.02s | 32 KB | 80 | 3.36% | 65.1 MB | 0.401 | | 3 | 0.02s | 64 KB | 60 | 3.39% | 65.5 MB | 0.431 | | 4 | 0.10s | 128 KB | 60 | 2.93% | 71.9 MB | 0.437 |
Rank 3 is not on the Pareto front because rank 2 is strictly better on both CPU and memory.
The two clusters in the front represent different trade-off strategies: large frame + right-sized minor heap (ranks 1 and 4) optimises CPU, while tiny heap + small frame (ranks 2 and 3) squeezes out a few more MB at the cost of slightly higher CPU.
50-minute confirmation
The 5-minute matrix runs are enough to see the trend, but not long enough to let memory stabilise — startup and warm-up effects dominate the early samples and can bias the averages. We ran a dedicated 50-minute three-way comparison (baseline, top-1, top-2) to get a cleaner picture.
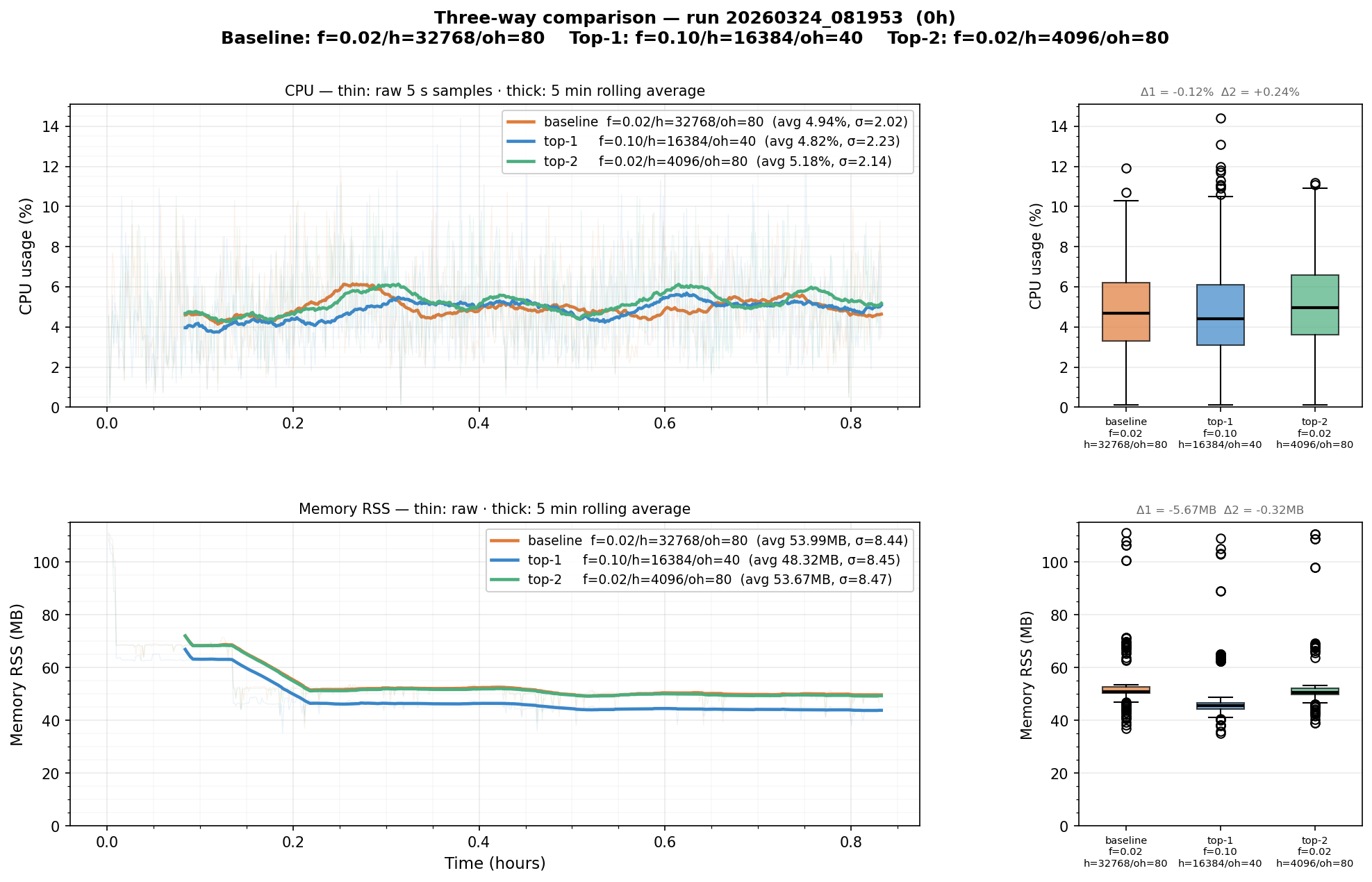
| Configuration | CPU avg | CPU max | Mem avg | Mem max | |—|—|—|—|—| | baseline (f=0.02, h=256KB, oh=80) | 4.94% | 11.90% | 54.0 MB | 111.2 MB | | top-1 (f=0.10, h=128KB, oh=40) | 4.82% | 14.40% | 48.3 MB | 109.1 MB | | top-2 (f=0.02, h=32KB, oh=80) | 5.18% | 11.20% | 53.7 MB | 110.6 MB |
Top-1 wins on both average CPU (−0.12%) and average memory (−5.7 MB, −11%). Top-2 does not improve on the baseline in the longer run.
The longer test also revealed something the 5-minute runs obscured: top-2’s tiny 32 KB minor heap causes the 0.02 s frame buffer (~14 KB) to compete for space with other allocations more aggressively, producing spikier behaviour even though the averages look similar.
Raw results (125 combinations)
3-axis matrix — run 20260323_233236
Command: ./liquidsoap_wrapper.sh | Duration: 300s/batch | Interval: 5s
FRAME HEAP(w) HEAP OVERHEAD SAMPLES CPU AVG CPU MAX CPU σ MEM AVG MEM MAX MEM σ
────────────────────────────────────────────────────────────────────────────────────────────────────────────
0.02 4096 32KB 40 59 4.17% 8.50% 1.48 62.3MB 84.6MB 3.0MB
0.02 4096 32KB 60 59 3.86% 9.00% 1.77 65.6MB 72.3MB 1.9MB
0.02 4096 32KB 80 59 3.36% 7.20% 1.27 65.1MB 94.6MB 4.4MB
0.02 4096 32KB 100 59 3.57% 7.80% 1.58 70.2MB 86.6MB 3.3MB
0.02 4096 32KB 120 59 3.77% 9.30% 1.80 73.1MB 88.3MB 3.1MB
0.02 8192 64KB 40 59 3.78% 9.40% 1.74 62.4MB 81.9MB 2.6MB
0.02 8192 64KB 60 59 3.39% 7.20% 1.47 65.5MB 89.1MB 3.3MB
0.02 8192 64KB 80 59 3.65% 6.80% 1.44 68.6MB 89.1MB 2.9MB
0.02 8192 64KB 100 59 3.38% 8.20% 1.69 70.3MB 86.1MB 3.3MB
0.02 8192 64KB 120 59 3.40% 7.70% 1.48 72.8MB 77.7MB 3.2MB
0.02 16384 128KB 40 59 4.06% 9.20% 1.65 65.2MB 110.3MB 10.0MB
0.02 16384 128KB 60 59 4.16% 8.80% 1.72 69.0MB 108.6MB 9.3MB
0.02 16384 128KB 80 59 4.11% 9.40% 1.83 69.0MB 139.1MB 16.2MB
0.02 16384 128KB 100 59 4.04% 9.40% 1.82 72.3MB 101.3MB 7.1MB
0.02 16384 128KB 120 59 4.09% 9.00% 1.52 74.6MB 103.8MB 7.0MB
0.02 32768 256KB 40 59 4.22% 10.20% 1.79 64.5MB 102.9MB 8.9MB
0.02 32768 256KB 60 59 3.73% 7.10% 1.50 68.5MB 110.1MB 9.8MB
0.02 32768 256KB 80 59 4.11% 9.40% 1.78 68.7MB 135.9MB 15.4MB
0.02 32768 256KB 100 59 3.67% 7.50% 1.42 74.7MB 113.9MB 8.8MB
0.02 32768 256KB 120 59 4.05% 8.20% 1.82 74.7MB 107.7MB 8.6MB
0.02 65536 512KB 40 59 4.36% 9.30% 1.98 71.4MB 115.6MB 13.9MB
0.02 65536 512KB 60 59 4.47% 8.80% 1.79 75.5MB 114.9MB 13.2MB
0.02 65536 512KB 80 59 4.24% 9.40% 1.91 78.6MB 145.1MB 22.0MB
0.02 65536 512KB 100 59 3.52% 7.00% 1.45 78.3MB 117.0MB 11.8MB
0.02 65536 512KB 120 59 3.78% 8.90% 1.55 82.1MB 119.1MB 11.3MB
0.04 4096 32KB 40 59 4.48% 9.30% 1.88 70.3MB 114.9MB 15.2MB
0.04 4096 32KB 60 59 4.29% 11.20% 2.05 73.8MB 115.2MB 14.4MB
0.04 4096 32KB 80 59 3.82% 8.30% 1.57 74.0MB 117.0MB 12.7MB
0.04 4096 32KB 100 59 4.15% 9.10% 1.76 82.4MB 125.8MB 12.9MB
0.04 4096 32KB 120 59 3.96% 8.70% 1.73 83.5MB 119.1MB 10.7MB
0.04 8192 64KB 40 59 3.75% 6.70% 1.43 72.9MB 112.8MB 15.8MB
0.04 8192 64KB 60 59 4.29% 10.10% 1.98 77.7MB 113.9MB 14.9MB
0.04 8192 64KB 80 59 3.78% 9.10% 1.62 75.5MB 118.4MB 15.1MB
0.04 8192 64KB 100 59 3.82% 8.20% 1.75 83.3MB 118.9MB 14.2MB
0.04 8192 64KB 120 59 4.06% 8.40% 1.61 83.0MB 117.6MB 12.0MB
0.04 16384 128KB 40 59 4.28% 9.70% 1.87 74.6MB 113.9MB 16.0MB
0.04 16384 128KB 60 59 4.29% 10.20% 1.91 74.5MB 117.1MB 14.8MB
0.04 16384 128KB 80 59 4.44% 9.80% 1.98 82.0MB 144.0MB 24.6MB
0.04 16384 128KB 100 59 3.71% 7.10% 1.49 83.2MB 113.8MB 15.0MB
0.04 16384 128KB 120 59 3.37% 7.40% 1.34 84.1MB 114.1MB 14.1MB
0.04 32768 256KB 40 59 4.42% 9.70% 1.95 72.8MB 116.0MB 15.5MB
0.04 32768 256KB 60 59 4.20% 9.20% 1.96 77.0MB 116.0MB 14.7MB
0.04 32768 256KB 80 59 3.97% 9.80% 1.82 79.7MB 143.5MB 24.0MB
0.04 32768 256KB 100 59 3.68% 6.90% 1.46 82.2MB 116.5MB 14.6MB
0.04 32768 256KB 120 59 3.87% 9.40% 1.67 83.9MB 116.8MB 14.1MB
0.04 65536 512KB 40 59 4.75% 9.30% 1.88 73.5MB 116.6MB 13.8MB
0.04 65536 512KB 60 59 4.13% 9.10% 1.88 77.9MB 116.5MB 14.9MB
0.04 65536 512KB 80 59 3.24% 7.80% 1.37 81.3MB 144.5MB 24.5MB
0.04 65536 512KB 100 59 3.78% 7.30% 1.55 79.8MB 118.3MB 11.8MB
0.04 65536 512KB 120 59 3.98% 8.30% 1.62 83.7MB 119.5MB 11.9MB
0.06 4096 32KB 40 59 4.47% 10.60% 2.10 69.7MB 119.2MB 16.0MB
0.06 4096 32KB 60 59 4.27% 9.80% 2.07 75.3MB 116.0MB 15.2MB
0.06 4096 32KB 80 59 4.07% 9.10% 1.84 79.7MB 146.1MB 23.9MB
0.06 4096 32KB 100 59 4.14% 8.80% 1.64 82.4MB 116.2MB 14.7MB
0.06 4096 32KB 120 59 4.09% 7.90% 1.72 84.3MB 116.6MB 14.2MB
0.06 8192 64KB 40 59 4.02% 8.00% 1.68 72.5MB 115.5MB 15.6MB
0.06 8192 64KB 60 59 4.11% 9.10% 1.83 73.4MB 118.8MB 15.0MB
0.06 8192 64KB 80 59 4.17% 9.00% 1.89 79.8MB 145.4MB 23.2MB
0.06 8192 64KB 100 59 3.65% 8.30% 1.54 81.5MB 115.1MB 14.7MB
0.06 8192 64KB 120 59 4.34% 9.20% 1.89 83.2MB 114.8MB 13.1MB
0.06 16384 128KB 40 59 4.04% 10.50% 1.71 62.6MB 65.1MB 2.6MB
0.06 16384 128KB 60 59 3.86% 9.40% 1.71 67.4MB 68.9MB 3.9MB
0.06 16384 128KB 80 59 4.31% 8.80% 1.91 69.2MB 73.2MB 3.1MB
0.06 16384 128KB 100 59 3.66% 8.80% 1.65 72.4MB 73.8MB 4.4MB
0.06 16384 128KB 120 59 3.99% 8.50% 1.69 74.1MB 75.6MB 5.2MB
0.06 32768 256KB 40 59 4.25% 10.00% 1.70 64.3MB 64.9MB 2.7MB
0.06 32768 256KB 60 59 3.49% 7.60% 1.37 68.3MB 69.7MB 3.7MB
0.06 32768 256KB 80 59 4.49% 9.70% 1.98 68.5MB 72.6MB 3.6MB
0.06 32768 256KB 100 59 3.88% 8.80% 1.78 72.5MB 73.5MB 4.8MB
0.06 32768 256KB 120 59 3.94% 10.50% 1.83 77.2MB 79.2MB 5.7MB
0.06 65536 512KB 40 59 4.12% 9.60% 1.87 75.7MB 117.7MB 17.0MB
0.06 65536 512KB 60 59 3.70% 8.70% 1.72 77.9MB 116.9MB 16.3MB
0.06 65536 512KB 80 59 3.79% 9.50% 1.69 80.9MB 122.5MB 16.2MB
0.06 65536 512KB 100 59 3.67% 9.00% 1.83 82.1MB 121.4MB 14.5MB
0.06 65536 512KB 120 59 3.54% 10.10% 1.69 86.2MB 117.0MB 16.0MB
0.08 4096 32KB 40 59 3.81% 10.50% 1.97 74.0MB 117.7MB 17.3MB
0.08 4096 32KB 60 59 3.70% 9.60% 1.62 77.3MB 117.9MB 17.2MB
0.08 4096 32KB 80 59 3.79% 7.40% 1.55 81.6MB 148.7MB 27.0MB
0.08 4096 32KB 100 59 3.97% 9.20% 1.87 85.2MB 118.9MB 18.1MB
0.08 4096 32KB 120 59 3.79% 6.90% 1.43 89.0MB 126.1MB 19.3MB
0.08 8192 64KB 40 59 3.91% 9.20% 1.86 66.4MB 110.3MB 11.6MB
0.08 8192 64KB 60 59 3.44% 9.90% 1.75 71.9MB 109.0MB 9.5MB
0.08 8192 64KB 80 59 3.72% 8.20% 1.68 70.7MB 137.7MB 17.3MB
0.08 8192 64KB 100 59 3.62% 9.50% 1.58 76.0MB 108.2MB 8.5MB
0.08 8192 64KB 120 59 3.42% 7.10% 1.45 80.4MB 106.8MB 7.5MB
0.08 16384 128KB 40 59 3.69% 8.50% 1.78 66.3MB 105.0MB 10.3MB
0.08 16384 128KB 60 59 3.81% 8.20% 1.71 70.5MB 109.9MB 10.9MB
0.08 16384 128KB 80 59 3.62% 9.10% 1.67 72.0MB 104.5MB 9.0MB
0.08 16384 128KB 100 59 3.48% 8.20% 1.60 74.3MB 105.2MB 8.2MB
0.08 16384 128KB 120 59 3.76% 8.40% 2.02 78.0MB 107.8MB 8.4MB
0.08 32768 256KB 40 59 3.89% 7.00% 1.47 69.6MB 115.2MB 13.8MB
0.08 32768 256KB 60 59 3.25% 6.80% 1.39 72.5MB 111.4MB 12.3MB
0.08 32768 256KB 80 59 3.46% 6.60% 1.40 76.2MB 142.2MB 21.8MB
0.08 32768 256KB 100 59 3.04% 6.80% 1.26 77.0MB 114.6MB 10.7MB
0.08 32768 256KB 120 59 2.78% 5.70% 1.14 81.5MB 114.6MB 12.0MB
0.08 65536 512KB 40 59 3.74% 8.50% 1.53 70.4MB 115.3MB 13.2MB
0.08 65536 512KB 60 59 3.39% 8.20% 1.55 73.2MB 114.8MB 12.0MB
0.08 65536 512KB 80 59 3.88% 9.40% 1.89 77.4MB 143.7MB 21.3MB
0.08 65536 512KB 100 59 3.39% 8.40% 1.44 79.6MB 115.2MB 11.3MB
0.08 65536 512KB 120 59 3.07% 7.20% 1.20 81.9MB 117.2MB 8.9MB
0.10 4096 32KB 40 59 3.56% 8.10% 1.58 68.0MB 110.8MB 13.1MB
0.10 4096 32KB 60 59 3.36% 6.50% 1.49 71.6MB 108.8MB 12.1MB
0.10 4096 32KB 80 59 3.16% 6.40% 1.18 76.6MB 140.6MB 20.8MB
0.10 4096 32KB 100 59 3.01% 6.10% 1.29 77.9MB 110.2MB 9.4MB
0.10 4096 32KB 120 59 2.98% 6.10% 1.16 80.7MB 113.8MB 12.2MB
0.10 8192 64KB 40 59 3.30% 6.60% 1.23 67.3MB 106.5MB 11.8MB
0.10 8192 64KB 60 59 3.24% 7.80% 1.32 71.7MB 110.9MB 12.8MB
0.10 8192 64KB 80 59 2.85% 6.20% 1.30 74.1MB 137.2MB 21.1MB
0.10 8192 64KB 100 59 3.21% 6.60% 1.34 77.0MB 110.9MB 11.4MB
0.10 8192 64KB 120 59 3.06% 5.70% 1.26 79.3MB 111.2MB 10.4MB
0.10 16384 128KB 40 59 3.04% 6.10% 1.20 68.2MB 113.7MB 13.2MB
0.10 16384 128KB 60 59 2.93% 5.50% 1.12 71.9MB 110.4MB 12.4MB
0.10 16384 128KB 80 59 3.04% 6.00% 1.33 74.2MB 140.3MB 21.8MB
0.10 16384 128KB 100 59 2.98% 5.80% 1.23 75.8MB 109.3MB 10.8MB
0.10 16384 128KB 120 59 2.88% 6.10% 1.19 77.9MB 106.1MB 8.8MB
0.10 32768 256KB 40 59 3.26% 7.00% 1.34 68.0MB 106.5MB 11.5MB
0.10 32768 256KB 60 59 3.13% 7.10% 1.29 72.2MB 111.0MB 12.2MB
0.10 32768 256KB 80 59 2.99% 6.70% 1.26 75.0MB 141.2MB 21.1MB
0.10 32768 256KB 100 59 3.38% 6.60% 1.33 76.7MB 106.8MB 9.2MB
0.10 32768 256KB 120 59 2.83% 6.30% 1.31 79.5MB 111.3MB 9.5MB
0.10 65536 512KB 40 59 3.82% 7.30% 1.60 67.3MB 121.3MB 7.9MB
0.10 65536 512KB 60 59 3.86% 7.10% 1.47 72.0MB 117.6MB 6.7MB
0.10 65536 512KB 80 59 3.67% 6.70% 1.47 76.4MB 144.0MB 11.3MB
0.10 65536 512KB 100 59 3.76% 6.90% 1.48 76.7MB 117.8MB 6.0MB
0.10 65536 512KB 120 59 3.63% 6.60% 1.39 80.5MB 121.1MB 6.0MB
Applying the winning configuration
The winning combination translates directly to a few lines at the top of the script:
settings.frame.duration := 0.10
runtime.gc.set(runtime.gc.get().{
minor_heap_size = 16384, # 128 KB
space_overhead = 40
})
Or, if you want to keep the values configurable via command-line flags as we did:
frame_duration = getopt(default="0.10", "-D")
settings.frame.duration := float_of_string(frame_duration)
minor_heap_size = getopt(default="16384", "-H")
space_overhead = getopt(default="40", "-O")
runtime.gc.set(runtime.gc.get().{
minor_heap_size = int_of_string(minor_heap_size),
space_overhead = int_of_string(space_overhead)
})
Conclusion
A 0.12% CPU reduction and 11% memory reduction per process may sound small, but when running 20 instances on a shared server, it is equivalent to recovering ~2 full instances worth of memory — enough to meaningfully affect capacity planning.
These numbers should be taken with a grain of salt. They are specific to one script, one hardware setup, and a controlled test environment. A script doing heavy DSP, video processing, or complex routing will have very different allocation patterns, and may not benefit from the same configuration at all. The OCaml GC defaults are deliberately conservative and work well across a wide range of workloads — we would not recommend changing them globally.
More broadly, GC tuning is never purely systematic: the experiment narrows the search space and surfaces the trade-offs, but the final call requires judgment about what matters in your specific production environment. CPU variance, latency spikes, interaction with other processes on the host — none of that is captured by a 5-minute matrix sweep. Treat the results as a starting point for pragmatic manual tuning, not as a definitive answer.
What we hope is useful here is the tooling: the test harness, the heatmap and Pareto visualization approach, and the general methodology of framing GC tuning as a multi-objective search. Those transfer to other scripts and other OCaml applications well beyond Liquidsoap.
The general principle does transfer: figure out your dominant allocation (for Liquidsoap, it is almost always the audio frame buffer), size your minor heap to hold it comfortably (roughly 2–3×), and tune space_overhead downward until the memory savings are no longer worth the marginal GC cost. But always verify on your own workload.